# 세트 생성1
st = {1, 2, 3, 1, 1, 4}
print(st){1, 2, 3, 4}{}를 사용하여 세트를 직접 정의하는 방법{} 안에 원소(element)를 ,로 구분하여 나열함set() 함수를 사용하여 세트를 생성하는 방법set() 함수를 사용해야 함# 세트 생성1
st = {1, 2, 3, 1, 1, 4}
print(st){1, 2, 3, 4}# 세트 생성2
st = set({1, 2, 3, 1, 1, 4})
print(st){1, 2, 3, 4}# 세트 생성3 : 세트는 해시 가능한(immutable) 자료형을 저장할 수 있음
st = {1, 3.14, "Hello", True, (1, 2, 3), "Hello", 1, 1, 1}
print(st){1, 3.14, 'Hello', (1, 2, 3)}# 세트 생성4: iterable 객체 사용
st = set("Hello")
print(st){'e', 'l', 'H', 'o'}# 세트 생성5 : iterable 객체 사용
st1 = set([1, 2, 3, 1, 1, 4])
st2 = set((1, 2, 3, 1, 1, 4))
print(st1)
print(st2){1, 2, 3, 4}
{1, 2, 3, 4}* : 세트의 개별 원소를 분리하여 다른 세트로 전개 - (예) {*세트}# 세트 전개
st = {1, 2, 3, 1, 1, 4}
print({*st, *st})
print([11, 12, *st, 20]){1, 2, 3, 4}
[11, 12, 1, 2, 3, 4, 20]| 연산 | 연산자 | 함수 |
|---|---|---|
| 합집합 | | | union() |
| 교집합 | & | intersection() |
| 차집합 | - | difference() |
| 대칭차집합 | ^ | symmetric_difference() |
| 부분집합 여부 | <= | issubset() |
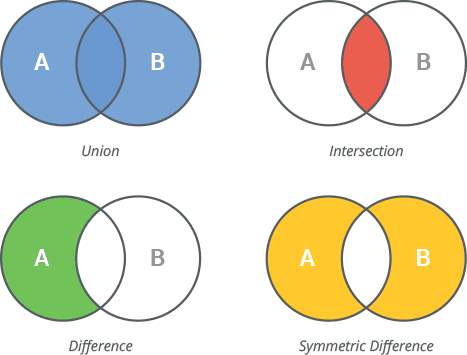
# 세트 연산1
A = {1, 2, 3}
B = {3, 4, 5}
print(A | B) # 합집합
print(A & B) # 교집합
print(A - B) # 차집합
print(A ^ B) # 대칭차집합
print(A <= B) # 부분집합 여부{1, 2, 3, 4, 5}
{3}
{1, 2}
{1, 2, 4, 5}
False# 세트 연산2
A = {1, 2, 3}
B = {3, 4, 5}
print(A.union(B))
print(A.intersection(B))
print(A.difference(B))
print(A.symmetric_difference(B))
print(A.issubset(B)){1, 2, 3, 4, 5}
{3}
{1, 2}
{1, 2, 4, 5}
False# 세트 연산3 : 여러 개의 세트를 연쇄적으로 한 번에 연산 가능
A = {1, 2, 3}
B = {3, 4, 5}
C = {5, 6, 7}
# 연산자 사용
print(A | B | C)
print(A & B & C)
# 메소드 사용
print(A.union(B, C))
print(A.intersection(B, C)){1, 2, 3, 4, 5, 6, 7}
set()
{1, 2, 3, 4, 5, 6, 7}
set()| 함수 | 설명 |
|---|---|
| add() | - 새로운 값을 세트에 추가 |
| update() | - 여러 개 값을 세트에 추가 |
| pop() | - 임의의 값을 삭제하고 그 값을 반환 - 어떤 값을 삭제할지 예측 불가능 |
| remove() | - 세트에서 일치하는 값을 삭제 - 일치하는 값이 없으면 오류가 발생함 |
| discard() | - 세트에서 일치하는 값을 삭제 - 일치하는 값이 없어도 오류가 발생하지 않음 |
| clear() | - 세트의 모든 원소를 삭제 |
| in 연산자 | 세트 내부에 특정 값이 있다면 True, 없다면 False를 반환 |
# 세트에 한 개의 원소 추가
st = {1, 2, 3}
st.add(6) # 실행 결과로 아무것도 출력하지 않음
print(st) # st 원본 값이 변함{1, 2, 3, 6}# 세트에 여러 개의 원소 추가
st = {1, 2, 3}
st.update([1, 2, 6]) # 리스트 사용
print(st)
st.update((1, 7)) # 튜플 사용
print(st)
st.update({8, 9}) # 세트 사용
print(st){1, 2, 3, 6}
{1, 2, 3, 6, 7}
{1, 2, 3, 6, 7, 8, 9}# 임의의 원소 삭제
st = {1, 2, 3}
result = st.pop() # 임의의 원소를 삭제 후 반환
print(st) # st 원본 값이 변함
print(result){2, 3}
1# 일치하는 값 삭제1
st = {1, 2, 3}
st.remove(3)
print(st){1, 2}# 일치하는 값 삭제2 : remove() 함수는 일치하는 값이 없으면 오류가 발생함
#st = {1, 2, 3}
#st.remove(4)
#print(st)# 일치하는 값 삭제3
st = {1, 2, 3}
st.discard(3)
print(st){1, 2}# 일치하는 값 삭제4 : discard() 함수는 일치하는 값이 없어도 오류가 발생하지 않음
st = {1, 2, 3}
st.discard(4)
print(st){1, 2, 3}# 세트 모든 원소 삭제
st = {1, 2, 3}
st.clear()
print(st)set()# 특정값 찾기
st = {1, 2, 3}
print(3 in st)
print(6 in st)True
False{식 for 변수 in 반복범위 if 조건식}
# 이메일 리스트에서 '@'가 포함된 유효한 이메일 주소만 추출
emails = ["user1@gmail.com", "user2", "test@yahoo.com", "invalid_email", "hello@naver.com"]
valid_emails = {e for e in emails if "@" in e}
print(valid_emails){'user1@gmail.com', 'hello@naver.com', 'test@yahoo.com'}# 문장에서 알파벳 문자만 추출 (중복 제거)
sentence = "Python is amazing! 123"
unique_chars = {char.lower() for char in sentence if char.isalpha()}
print(unique_chars){'y', 't', 'i', 'z', 'h', 'n', 'a', 'g', 's', 'm', 'o', 'p'}# 주어진 숫자 리스트에서 짝수의 제곱을 저장하는 세트
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
even_squares = {n**2 for n in numbers if n % 2 == 0}
print(even_squares) {64, 100, 4, 36, 16}# 웹사이트 방문 기록에서 도메인만 추출 (중복 제거)
urls = ["https://google.com", "http://example.com", "https://google.com", "https://openai.com"]
domains = {url.split("//")[1] for url in urls}
print(domains){'google.com', 'example.com', 'openai.com'}# 두 개의 리스트에서 공통된 단어만 저장 (중복 없이)
words1 = ["apple", "banana", "cherry", "durian"]
words2 = ["banana", "durian", "fig", "grape"]
common_words = {word for word in words1 if word in words2}
print(common_words) {'durian', 'banana'}